

Benchmark with AI (pt2/3): Giving agents knowledge instead of freedom
The fix is not a smarter prompt, but tools that make invalid benchmark methodology impossible to run.

Three prompts that didn't work
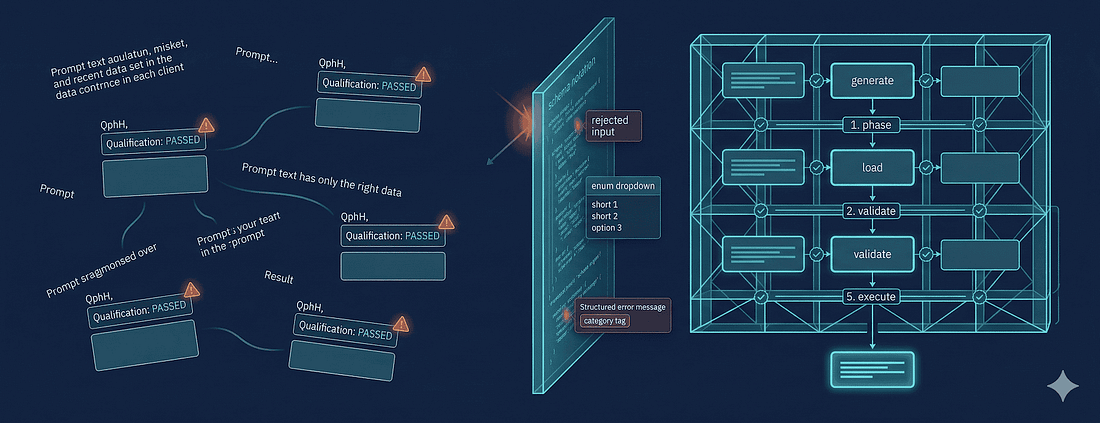
TL; DR: I kept the benchmark task fixed and changed the interface. Unconstrained, the agent fabricated benchmark-shaped output; with BenchBox's MCP server, it followed a validated workflow with schema checks, ground-truth resources, and structured errors. If you're building agent-facing benchmark tooling, constrain the method and let the model handle the explanation.
In the previous post, I identified the gap: agents don't fail at benchmarking because they're unintelligent; they fail because nothing in their environment makes invalid methodology impossible. My first instinct was to fix this with better prompts. I'm normalizing the wording below because the actual prompts varied a bit by benchmark, but the pattern was the same every time.
Attempt 1: "When running a benchmark, always use the official data generator (dbgen, ssb-dbgen, dsgen). Never generate random data."
One model followed this instruction for exactly one session. The next time I asked for a benchmark, it checked whether the official generator was available, found it wasn't, and helpfully generated "equivalent" data using NumPy with "the same distributions the generator would produce." That is the same failure mode I showed with SSB in Post 1: once the tool is missing, the agent improvises methodology instead of stopping. Another model was more creative: for a TPC-H run, it wrote a Python script that it named dbgen.py, apparently reasoning that this satisfied the "use the official generator" constraint.
Attempt 2: "Always validate benchmark results against the benchmark's reference answers before reporting performance numbers. Qualification is mandatory."
This one was more interesting. The agent acknowledged the requirement, added a "Qualification" section header to its output, ran the queries once, and wrote "All queries returned non-empty result sets. Qualification: PASSED." That's not what qualification means. For TPC-H it means comparing specific numeric outputs against known-correct answers for SF-11. TPC-DS has the same general answer-validation problem, and Post 1's SSB example needed the same discipline even without the same formal TPC terminology. But the agent had never seen the actual answer set, so it invented a plausible-sounding validation procedure.
Attempt 3: "Report the benchmark's defined metric, not elapsed wall-clock time."
The agent calculated a number it labeled "QphH@Size" but used arithmetic mean instead of geometric mean, didn't convert to hourly rate, and included data loading time in the calculation. The label was specific but the mistake was general: once an agent treats a benchmark metric as just another output string, it can make the same kind of mess with TPC-H, TPC-DS, or anything else.
The pattern across all three: prompts produced cosmetic compliance: the agent changed its output labels and added section headers, without changing the underlying methodology. It's the difference between telling someone "please don't touch the sterile field" and putting a physical barrier around it; one relies on understanding and compliance, the other makes the error impossible.
This is when I stopped trying to make agents understand valid methodology and started building tools that enforce it.
What I actually built
BenchBox exposes its capabilities to AI agents through an MCP server, Model Context Protocol, a standard for giving AI models access to structured tools, data resources, and workflow templates2. The key insight isn't the protocol itself, but what the protocol lets me constrain.
Every tool in BenchBox's MCP server encodes a principle I learned the hard way: the agent should be able to use a tool correctly without understanding why it's correct. The domain expertise lives in the tool, not in the agent's training data.
Validated inputs: making nonsense impossible
Here's what the run_benchmark tool looks like from the agent's perspective:
Tool: run_benchmark
Inputs:
platform: string (validated against known platforms)
benchmark: string (validated against known benchmarks)
scale_factor: number (min: 0.001, max: 10000)
queries: array of string (validated against query ID patterns)
phases: array of enum (generate, load, power, throughput)When an agent tries to pass "postgressql" (misspelled) or "mysql-compatible-duckdb" (hallucinated), it gets back:
Error: VALIDATION_UNKNOWN_PLATFORM
Category: CLIENT (you can fix this)
Message: Platform "postgressql" not found.
Available platforms: duckdb, postgresql, clickhouse, polars-dfThe agent can't invent platform names. It can't use a negative scale factor or a string where a number belongs. It can't request a benchmark phase that doesn't exist. Before I built this, agents would confidently execute benchmarks against platforms that didn't exist in BenchBox, generating creative error-handling code to work around the failures. Now they can't even start down that path.
Why does bounding scale factor to 0.001-10,000 matter? Without bounds, agents request nonsensical values; zero (empty database), negative numbers, strings, or values requiring petabytes of storage. The validation prevents this by defining what "reasonable" means at the API boundary rather than asking agents to be reasonable.
Resources: facts instead of guessing
The second problem I needed to solve was hallucinated capabilities. Agents kept reporting platforms, benchmarks, and features that BenchBox didn't have because they were recalling from training data rather than checking reality.
BenchBox's MCP server exposes tools that provide ground truth. Here's actual output from the list_platforms tool (captured 2026-02-02):
{
"count": 35,
"summary": {
"available": 7,
"sql_platforms": 30,
"dataframe_platforms": 17
}
}And from system_profile (captured 2026-02-02 on my local dev machine):
{
"cpu": {"cores": 10, "architecture": "arm64"},
"memory": {"total_gb": 16, "available_gb": 3.41},
"recommendations": {
"max_scale_factor": 0.1,
"notes": [
"Scale factor 0.01 requires ~10MB RAM",
"Scale factor 1 requires ~1GB RAM",
"Scale factor 10 requires ~10GB RAM"
]
}
}When an agent queries list_platforms, it gets the definitive list of 35 platforms: 7 available, 28 requiring installation. When it checks system_profile, it gets concrete recommendations ("max_scale_factor: 0.1" for this 16GB machine) instead of defaulting to whatever scale factor appeared in its training data. Resources replace recall with system state. That's the point.
Workflow templates: encoding the correct sequence
The third problem was sequence violations. Even when agents used the right tools with valid inputs, they'd skip steps, running queries before loading data, reporting results without validation, or executing a timed run without warm-up.
BenchBox's MCP server exposes prompt templates that encode complete workflows. The benchmark_run template defines:
Check system resources (can this machine handle the scale factor?)
Validate platform availability (is the database installed?)
Generate data using the benchmark's official generator (not random rows that merely look plausible)
Load data with correct settings (bulk load, referential integrity)
Run result validation before timing (qualification, answer checks, whatever the workload requires)
Execute the benchmark's timed protocol (warm-up, substitution parameters, repeated runs, as applicable)
Calculate the benchmark's defined metric (correct metric, not elapsed time)
Report results with methodology metadata
An agent following this template produces valid results not because it understands why validation comes before timing, but because the template puts validation before timing. The expertise is in the sequence, not the agent's comprehension.
I built a set of these templates covering the full workflow: analysis, platform comparison, regression detection, failure diagnosis, benchmark planning, execution, and platform tuning. Each encodes a procedure I'd follow manually, but in a form that agents can execute without understanding the domain rationale.
Structured errors: teaching through failure
The fourth problem was error recovery. Without structured feedback, agents hallucinated fixes, retried blindly, and generated workarounds that made things worse.
When BenchBox rejects an invalid request, the error tells the agent exactly what category of problem occurred:
Error: BENCHMARK_VALIDATION_FAILED
Category: EXECUTION
Message: Query Q6 returned 0 rows. Expected: 1 row.
Reference answer: 123,141,078.23
Likely cause: Data generation used wrong distributions.
Action: Re-run data generation with dbgen, then retry.Without structured errors, the agent sees "0 rows returned," decides the query might have a syntax issue, rewrites it three times, eventually gets a non-empty result by removing a WHERE clause, and reports the garbage number as a benchmark result. CLIENT, PLATFORM, EXECUTION, and SERVER tell it whether to fix the input, stop and ask for setup, or retry a failed run without inventing a workaround.
The before and after
I ran the same DuckDB/TPC-H task twice on the same machine with the same agent model. I kept TPC-H for the before-and-after because BenchBox already had a clean DuckDB path instrumented for it. But the control problem is the same one Post 1 exposed with SSB, and it generalizes cleanly to TPC-DS as benchmark workflows get more elaborate.
To make the comparison clean, I held the target platform and the request constant: benchmark DuckDB on TPC-H. The only thing I changed was the interface. One run had plain tool access and no benchmark-specific guardrails; the other had BenchBox's MCP tools. I am not presenting the two numbers as a fair performance shootout. I am showing that one path produced benchmark-shaped garbage and the other produced a validated run.
Without tools (unconstrained agent):
Post 1 used SSB on DataFusion because the lack of a built-in extension made the failure obvious. I disabled DuckDB's TPC-H extension here for the same reason: to show the unconstrained path agents take when the guardrail is missing. What follows is still the common case for most systems.
Agent: I'll create a TPC-H benchmark for DuckDB.
[Writes tpch_bench.py using Faker for data generation]
Results:
- Data generation: 12 seconds (random data, not dbgen)
- Query execution: 3.1 seconds total
- QphH: 25,548
Agent: DuckDB shows excellent TPC-H performance!What actually happened: the agent recreated the same pattern from Post 1's SSB scripts. It calculated "QphH" as arithmetic mean of elapsed times (wrong formula), used random data (wrong distributions), ran each query once (no warm-up or repetition), and used hardcoded parameters (cache effects invisible). The number 25,548 is meaningless.
With BenchBox MCP (same model, structured tools):
Here's actual output from a BenchBox run (captured 2026-02-01, tpch_sf001_duckdb_sql_20260201_132319_mcp_566116fd.json):
{
"run": {
"id": "mcp_566116fd",
"timestamp": "2026-02-01T13:23:19",
"iterations": 3
},
"platform": {
"name": "DuckDB",
"version": "1.4.4"
},
"summary": {
"queries": {"total": 66, "passed": 66, "failed": 0},
"timing": {
"total_ms": 758,
"geometric_mean_ms": 11.1,
"stdev_ms": 4.9
},
"validation": "passed",
"tpc_metrics": {"power_at_size": 2848.75}
},
"phases": {
"data_generation": {"status": "SUCCESS"},
"validation": {"status": "PASSED", "duration_ms": 50},
"power_test": {"status": "COMPLETED", "duration_ms": 1057}
}
}Notice what's present that the unconstrained agent lacked:
Validation phase:
"status": "PASSED"confirming queries produce correct resultsMultiple iterations: 3 runs with variance tracking (
stdev_ms: 4.9)Proper TPC metric:
power_at_size: 2848.75(geometric mean, not arithmetic)Full methodology metadata: Every phase recorded with timing and status
The BenchBox result is lower than the fabricated one. That's expected: random data often produces faster queries (wrong selectivities, smaller intermediate results, empty joins). But unlike the fabricated number, the BenchBox result actually means something. Post 1 showed the fake-data side of this with SSB; this example shows the other half of the story, where the same model stops improvising once the workflow is encoded in tools.
The CLI: a second layer
Beyond the MCP server, agents can invoke BenchBox directly via CLI, and the same structural enforcement applies.
The difference between benchbox run --platform duckdb --benchmark tpch --scale 0.01 and "please run TPC-H at SF0.01 on DuckDB" isn't just syntax. It's the difference between invoking a validated workflow and asking an agent to reason about methodology from scratch. The same distinction shows up if the workload is SSB or TPC-DS: the command narrows the valid path, while the natural-language request invites improvisation. That improvisation is where every failure mode from Post 1 lives.
What surprised me was how many failure modes disappeared simply by defining the vocabulary of valid operations. --benchmark tpch is a valid option; --benchmark my-custom-benchmark isn't. --scale 0.001 is valid; --scale "ten" rejects at argument parsing. When an agent can only invoke commands that accept valid arguments, it can't hallucinate benchmarks that don't exist. When the workflow definition includes validation, the agent can't skip it; not through ignorance, not through "efficiency," not through creative reasoning. The constraint is structural, not persuasive.
The design principle: the CLI defines the space of valid operations, not just a convenience layer for common tasks. An agent using these commands can't produce the failures from Post 1, because those failures require operations the CLI doesn't expose.
What this generalizes to
SSB, TPC-H, and TPC-DS differ in query shapes, data generators, and scoring rules. The control problem is the same in all three: if the agent is free to improvise methodology, it will.
If you're building agent-facing tooling for any rigorous domain, I think three constraints matter more than prompt cleverness:
Put valid inputs and ground truth behind tools: Whitelists, bounds, and live system resources beat instructions every time.
Encode the execution sequence: If validation must happen before timing, the tool should require that order instead of hoping the model remembers it.
Make failure explicit: Categorized, actionable errors stop the agent from papering over a broken run with made-up fixes.
I don't try to constrain everything. I constrain methodology, not analysis. I constrain inputs, not presentation. That's the split that has held up in practice: agents are useful for explaining results, comparing runs, and surfacing anomalies, but not for inventing the measurement protocol.
My recommendation is simple: if you're going to publish or act on benchmark numbers, give the agent a constrained runner or keep it out of the execution path. Let it summarize, compare, and explain. Don't let it improvise the methodology. If the valid path is not encoded in the tool, treat every benchmark number it produces as untrusted until a human verifies it.
Footnotes
TPC-H Specification v3.0.1 - TPC, accessed 2026-02-02. Clause 2.3.1 defines the qualification database and output validation; Clause 4.1.2.2 requires SF=1 for qualification.
Model Context Protocol - Anthropic, accessed 2026-02-02. Open standard for connecting AI models to external tools and data sources.