TL;DR: This post shows how the BenchBox MCP server (using Claude Code) automates benchmark discovery, execution, and investigative analysis. Using 5 simple prompts, I run and compare TPC-H at scale factor 1 with DataFusion's SQL and DataFrame support. I discover that TPC-H query 19 is 150% slower in DataFrame mode vs SQL. Root cause: the SQL optimizer extracts common join conditions from OR branches while the DataFrame API's explicit join-then-filter approach prevents the same optimization.
What I'm demonstrating
BenchBox exposes a Model Context Protocol (MCP) server that lets AI assistants interact with the benchmarking framework conversationally. You ask questions in plain language; the assistant calls BenchBox tools behind the scenes, exploring platforms, running benchmarks, comparing results, investigating anomalies. This post walks through one such session. I start with a question, explore the platform catalog, execute benchmarks, and follow an unexpected result down to its root cause.
Here are my 5 simple prompts for the agent:
"Which BenchBox platforms support both SQL and DataFrame execution and can run locally on this computer?"
"Run TPC-H sf1 Power testing with DataFusion using both SQL and DataFrame modes. Compare the runs and flag differences >10%."
"Show me the BenchBox head-to-head visualization comparing the results."
"Identify the query with largest performance regression. Explain what is different in the DataFrame and SQL executions."
"Write a technical analysis of the SQL vs DataFrame executions for this query. Use a diagram to show where they diverge"
Install BenchBox and setup MCP server
Create a virtual environment and install BenchBox with MCP support:
# Create uv virtual environment
uv venv ~/mcp_test/.venv
# Install benchbox with MCP extra
uv pip install --python ~/mcp_test/.venv/bin/python "benchbox[mcp]"
# Create project-level MCP server config
echo '{"mcpServers":{"benchbox":{"command":"~/mcp_test/.venv/bin/benchbox-mcp","args":[]}}}' > ~/mcp_test/.mcp.json
Sidebar: Claude asks for approval to use the BenchBox MCP tool, either every time (1) or the first time (2).
Tool use
benchbox - Read-only discovery tool() (MCP)
List all available database platforms.
Returns information about each platform including:…
Do you want to proceed?
❯ 1. Yes
2. Yes, and don't ask again for benchbox - Read-only discovery tool commands in ~/mcp_test
3. No
Exploring the platform catalog
prompt:
"Which BenchBox platforms support both SQL and DataFrame execution and can run locally on this computer?"
response:
Platforms Supporting Both SQL and DataFrame
Of BenchBox's 37 platforms, 13 support both SQL and DataFrame execution. Filtering to those that can run locally (not cloud/managed services):
It's installed and available on this system with all dependencies met (datafusion + pyarrow 23.0.0). It runs natively on ARM64 and is Arrow-native, so it's a natural fit for your Apple Silicon Mac (10-core, 16GB).
PySpark can run locally in standalone mode, but would need pyspark installed (uv pip install "benchbox[dataframe-pyspark]").
Why not the others?
The remaining 11 dual-mode platforms (Databricks, Athena Spark, Dataproc, EMR Serverless, Glue, Fabric Spark, Synapse Spark, Snowpark Connect, Quanton, etc.) are all cloud/managed services — they require remote infrastructure and credentials, not local execution.
Notable local-only platforms (single mode)
For context, you also have these local platforms ready but they only support one mode:
DuckDB (v1.4.4) — SQL only
Polars (v1.38.1) — DataFrame only
So if you want to compare SQL vs. DataFrame execution on the same engine locally, DataFusion is your only option right now.
I'll use DataFusion for this investigation, keeping the SQL-vs-DataFrame comparison on the same local engine, removing cloud infrastructure variance.
Running the benchmarks
prompt:
"Run TPC-H sf1 Power testing with DataFusion using both SQL and DataFrame modes. Compare the runs and flag differences >10%. These benchmarks will run locally so do not run them in parallel."
response:
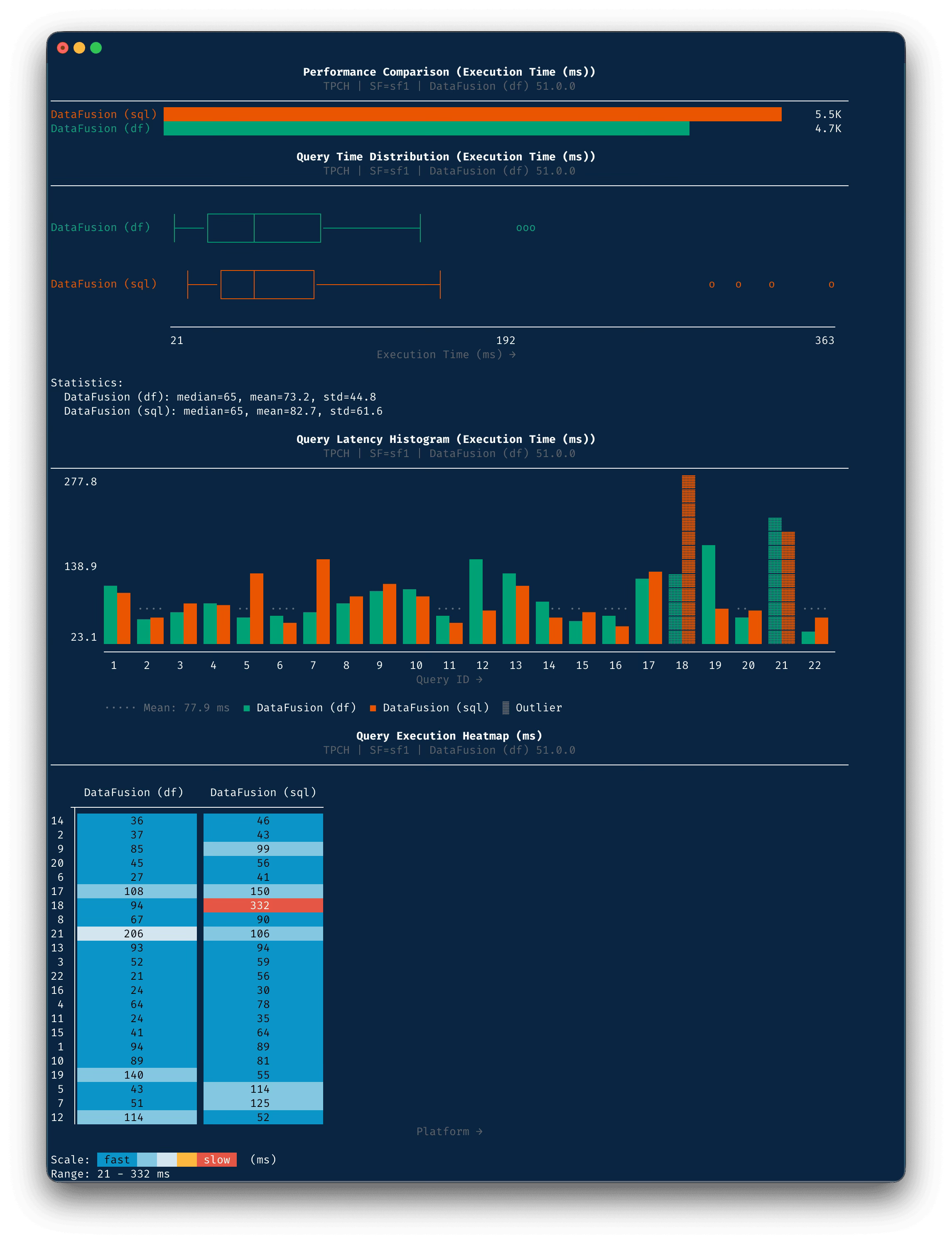
Results: DataFusion SQL vs DataFrame — TPC-H SF1
Both runs completed all 22 queries with 3 measurement iterations on DataFusion 51.0.0.
DataFrame mode is broadly faster — 16 of 22 queries improved, many substantially. The DataFrame API bypasses SQL parsing and can express optimizations more directly to the execution engine.>
Three significant regressions stand out — Q19, Q12, and Q21 are all dramatically slower in DataFrame mode (2-2.5x). These likely involve query patterns where the hand-written DataFrame code generates a les>s >optimal plan than what the SQL optimizer produces. Q19
involves complex disjunctive predicates (OR conditions), Q12 has ordered aggregation, and Q21 involves multi-level correlated subqueries — all patterns where SQL optimization heuristics can outperform manual >DataFrame construction.
Q18 is the standout improvement — 332ms (SQL) vs 94ms (DF), a 3.5x improvement. This large-order query with HAVING clause and nested aggregation appears to benefit significantly from the DataFrame API's more direct expression of the computation.
The biggest percentage regression is Q19: DataFrame mode is 2.55x slower (+154.5%). I will investigate Q19.
Visual comparison of SQL vs DataFrame
prompt:
"Show me the BenchBox head-to-head visualization comparing the results."
response:
Embedded image to show colors, Substack code blocks do not support ANSI color codes
Most queries improved in DataFrame mode, but Q19, Q12, and Q21 are large regressions that dominate the risk profile.
Investigating the largest regression (Q19)
prompt:
"Identify the query with largest performance regression. Explain what is different in the DataFrame and SQL executions."
response:
Q19: Discounted Revenue — Root Cause Analysis
The Query
Q19 computes revenue for parts matching three independent sets of conditions joined by OR. Each branch requires a join between lineitem (6M rows) and part (200K rows), plus brand/container/quantity/size filters.
What the SQL Optimizer Does
The SQL version uses an implicit comma-join with the join predicate inside the OR:
FROM lineitem, part
WHERE (p_partkey = l_partkey AND p_brand = 'Brand#12' AND ...)
OR (p_partkey = l_partkey AND p_brand = 'Brand#23' AND ...)
OR (p_partkey = l_partkey AND p_brand = 'Brand#34' AND ...)
DataFusion's SQL optimizer can analyze this structure and:
Extract the common join predicate — p_partkey = l_partkey appears in all three OR branches, so it's factored out as the hash join condition
Extract common filter predicates — l_shipmode IN ('AIR', 'AIR REG') and l_shipinstruct = 'DELIVER IN PERSON' are identical across all branches and get pushed down to a lineitem scan filter
Push part-side predicates filter — p_brand IN ('Brand#12','Brand#23','Brand#34') and p_size BETWEEN 1 AND 15 (the union of all size ranges) can be used to filter the part scan
This dramatically shrinks both sides of the join before it executes.
The problem is predicate pushdown through disjunctions is hard. While the top-level l_shipmode and l_shipinstruct predicates sit outside the OR (the DataFrame code does structure this well), the OR branches >themselves contain predicates on both sides of the join (p_brand from part, l_quantity from lineitem). The optimizer can't cleanly decompose and push these mixed-table predicates down through the OR.
The DataFrame code could be restructured to match what the SQL optimizer does automatically — pre-filter both tables, then join, then apply the residual OR:
# Pre-filter common predicates BEFORE the join
li = lineitem.filter(
col("l_shipmode").is_in(ship_modes)
& (col("l_shipinstruct") == lit("DELIVER IN PERSON"))
)
pt = part.filter(
col("p_brand").is_in([brand1, brand2, brand3])
& (col("p_size") >= lit(1))
& (col("p_size") <= lit(15))
)
# Join the reduced inputs, then apply branch-specific filters
result = (
li.join(pt, left_on="l_partkey", right_on="p_partkey")
.filter(branch1 | branch2 | branch3)
...
)
This is the fundamental tradeoff: SQL optimizers have decades of research on predicate extraction and pushdown through disjunctions. DataFrame APIs express computation imperatively, putting the optimization burden on the developer. Q19 is a textbook case — its deeply nested OR-of-AND structure is exactly the pattern where SQL optimizers shine and naive DataFrame construction falls short.
The SQL optimizer extracts the common join condition from OR branches and pushes filters down. In this plan shape, DataFusion's DataFrame path cannot do the same rewrite once the join is explicitly fixed before the filter.
The predicate extraction gap
prompt:
"Write a technical analysis of the SQL vs DataFrame executions for this query. Use a diagram to show where they diverge."
response:
Compilation Path Divergence
SQL Path DataFrame Path
──────── ──────────────
FROM lineitem, part lineitem.join(part, partkey)
WHERE (key=key AND ...) .filter(common & (b1|b2|b3))
OR (key=key AND ...) │
OR (key=key AND ...) │
▼ ▼
┌──────────────────────────┐ ┌──────────────────────────┐
│ Parser → CrossJoin │ │ Builder → InnerJoin │
│ Join key INSIDE the OR │ │ Join key ALREADY SET │
└────────────┬─────────────┘ └────────────┬─────────────┘
▼ │
┌──────────────────────────┐ (rule does not fire:
│ ExtractEquijoinPredicate │ join already resolved)
│ │ │
│ Finds partkey = partkey │ │
│ in ALL branches → hoist │ │
│ as join key │ │
└────────────┬─────────────┘ │
▼ ▼
┌──────────────────────────┐ ┌──────────────────────────┐
│ PushDownFilter │ │ PushDownFilter │
│ │ │ │
│ Clean single-table preds │ │ OR branches mix both │
│ after join key removed: │ │ tables (p_brand AND │
│ • shipmode → lineitem │ │ l_quantity) so cannot │
│ • shipinstruct → lineitem│ │ push to either side │
│ • p_size >= 1 → part │ │ │
│ • p_brand IN → part │ │ Only top-level ANDs push:│
│ │ │ • shipmode → lineitem │
│ Both scans filtered │ │ • shipinstruct → lineitem│
└────────────┬─────────────┘ └────────────┬─────────────┘
▼ ▼
HashJoin(partkey) Filter(OR(b1,b2,b3))
├─ Scan lineitem [2 preds] └─ HashJoin(partkey)
│ ~908K rows ├─ Scan lineitem [2 preds]
└─ Scan part [2 preds] │ ~908K rows
~small subset └─ Scan part [no filter]
200K rows
▼ ▼
55 ms 140 ms
Where the gap opens
The critical moment is ExtractEquijoinPredicate. This optimizer rule scans the WHERE clause for equijoin conditions. In SQL mode, it finds p_partkey = l_partkey buried inside all three OR branches and hoists it out as the join key. The remaining predicate, now free of the join condition, becomes a simpler OR-of-filters that PushDownFilter can decompose more aggressively.
In DataFrame mode, this rule never fires because the join is already explicit. The developer did the right thing by specifying the join key directly, but in doing so, they prevented the optimizer from ever seeing the predicate structure that SQL mode exploits.
The second gap is in PushDownFilter. DataFusion's filter pushdown can extract common factors from OR branches using the identity (A∧B) ∨ (A∧C) → A ∧ (B∨C). In SQL mode, after the join condition is extracted, the remaining branches are cleaner, containing single-table predicates that factor neatly. In DataFrame mode, each OR branch still contains predicates from both tables (p_brand from part, l_quantity from lineitem), which prevents the optimizer from attributing them to one side of the join.
The net effect: SQL mode filters the part table down to a small subset (3 brands, size 1-15) before joining. DataFrame mode joins all 200K part rows against the filtered lineitem, producing a much larger intermediate result that the OR filter must then evaluate row by row.
"For expressions like (A AND B) OR (C AND D), the optimizer transforms to: ((A AND B) OR (C AND D)) AND (A OR C)"
The optimizer can only extract common factors across OR branches. It cannot recognize that a join condition appears in every branch, hoist it out, and convert the pattern to JOIN ON key WHERE (filters1 OR filters2 OR filters3).
Both [SQL and DataFrame] are translated into the same LogicalPlan... the DataFrame API builds the LogicalPlan directly using LogicalPlanBuilder.
The same optimizer processes both paths, but the initial plan structure determines what optimizations are possible. SQL's implicit join gives the optimizer more room to restructure; DataFrame's explicit join is a constraint the optimizer respects.
This gap is caused by the difference in how query APIs are interpreted before execution, it is not caused by any specific DataFrame API overhead.
Learnings
The BenchBox MCP enables Claude Code to quickly compare DataFusion's SQL vs DataFrame modes, identify Q19 as a 2.55x regression (+154.5%), and trace the source to predicate pushdown during query planning. A future post will contrast this with letting Claude Code try this _without_ the MCP (spoiler: slow, confident, and wrong).
This is a DataFusion-specific result, not a blanket statement about DataFrame APIs. Polars, PySpark, etc. all have different optimization capabilities and can make different planning choices on the same logical query shape.
For Q19 on DataFusion, SQL is faster because the optimizer extracts shared predicates from OR branches and pushes filters earlier. DataFusion's DataFrame path starts from the user-expressed plan shape, and does not get the SQL-only rewrites.
However, DataFrame is actually faster for relatively straightforward queries. 16 of the 22 TPC-H queries ran more quickly, including a 3.5x improvement on Q18. The impact of the optimization difference is query-specific.
My recommendation today: on DataFusion, prefer SQL for OR-heavy multi-table predicates like Q19, Q12, and Q21. Use DataFrame mode when query construction ergonomics matter and your workload resembles the 16 queries where DataFrame won.
Note that this is not a permanent DataFusion limitation. DataFusion is moving forward quickly and the optimizer keeps evolving. This specific gap could close in future releases.
Single-node, Apple Silicon, default DataFusion configuration, TPC-H Power test only
TPC-H DataFrame queries were created for BenchBox and are not officially provided.
BenchBox's DataFrame Q19 may not represent the best possible translation of the SQL query.
BenchBox's DataFusion integration reads from parquet files and operates in-memory.
Try it yourself
The full investigation, from platform discovery to query plan analysis, took one session. Connect the BenchBox MCP server to your AI assistant and start with a question like "Which platforms support both SQL and DataFrame execution?"
Or run directly via CLI:
$ uv run benchbox run --platform datafusion --benchmark tpch --scale 1
$ uv run benchbox run --platform datafusion-df --benchmark tpch --scale 1
$ uv run benchbox compare --head-to-head --runs {run_id_sql} {run_id_df}
If you find that you cannot reproduce this, please open an issue with your run result JSON files attached. The key signal to compare is whether Q19 remains above 2x on your hardware and DataFusion version.